









اگر تا به حال مجبور شده باشید یک متن طولانی را از روی عکس یا فایل اسکن شده تایپ کنید، احتمالاً متوجه شدهاید که این کار چقدر زمانبر و خستهکننده است. اینجاست که تکنولوژی OCR وارد میشود.
OCR ابزاری است که میتواند متن داخل تصاویر، فایلهای PDF اسکن شده یا حتی دستخط را به متن قابل ویرایش تبدیل کند. به زبان ساده، OCR پلی بین دنیای کاغذی و دنیای دیجیتال است.
در این مقاله به بررسی دقیق ، کاربردی درباره OCR و اینکه چگونه کار میکند و چه مزایا و کاربردهایی دارد و آیا واقعاً در ایران استفاده میشود یا نه میپردازیم.
OCR چیست؟
OCR مخفف عبارت Optical Character Recognition به معنی «تشخیص نوری کاراکتر» است.
این تکنولوژی با استفاده از پردازش تصویر و الگوریتمهای هوش مصنوعی، حروف و اعداد موجود در یک تصویر را شناسایی کرده و آنها را به متن دیجیتال تبدیل میکند.
بهعنوان مثال:
عکس گرفتن از یک صفحه کتاب
اسکن کردن یک فاکتور
تبدیل فایل PDF اسکن شده به متن قابل جستجو
همه اینها با OCR قابل انجام است.
نکته مهم این است که OCR فقط یک ابزار ساده تبدیل عکس به متن نیست؛ بلکه یک سیستم هوشمند است که:
خطوط متن را تشخیص میدهد
فاصله بین کلمات را درک میکند
فونتهای مختلف را شناسایی میکند
حتی در نسخههای پیشرفته دستخط را هم تشخیص میدهد
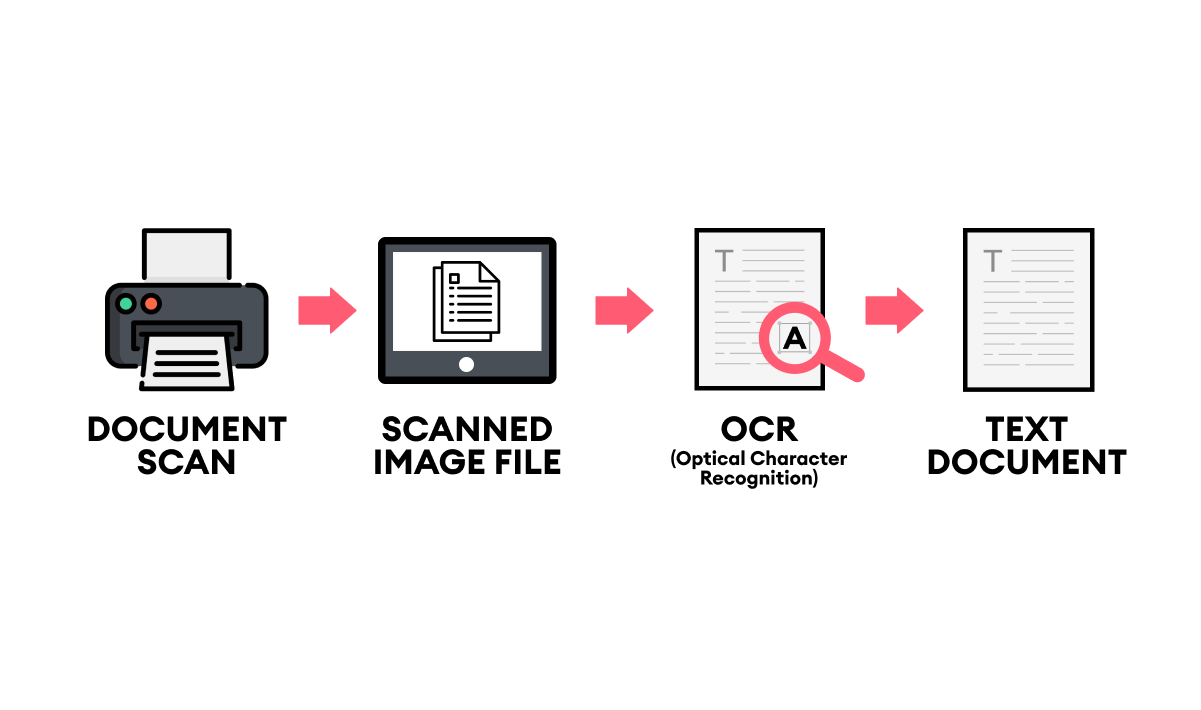
OCR چگونه کار میکند؟
فرآیند OCR چند مرحله دارد:
1. پیشپردازش تصویر
در این مرحله تصویر تمیز میشود:
حذف نویز
افزایش کنتراست
صاف کردن خطوط
2. تشخیص نواحی متنی
سیستم مشخص میکند کدام بخش تصویر شامل متن است و کدام بخش تصویر یا پسزمینه است.
3. شناسایی کاراکترها
الگوریتم با استفاده از مدلهای یادگیری ماشین حروف را تشخیص میدهد.
4. تبدیل به متن قابل ویرایش
در نهایت متن استخراج شده در قالب Word، TXT یا PDF قابل جستجو ارائه میشود.
مزایای OCR
استفاده از OCR فقط برای راحتی نیست؛ بلکه یک مزیت رقابتی برای کسبوکارها محسوب میشود.
صرفهجویی در زمان
به جای تایپ دستی صدها صفحه، در چند ثانیه متن استخراج میشود.
کاهش هزینهها
نیاز به نیروی انسانی برای ورود اطلاعات کاهش پیدا میکند.
جستجوی سریع در اسناد
اسناد اسکن شده دیگر فایل تصویری نیستند و میتوان داخل آنها جستجو کرد.
کاهش خطای انسانی
OCR با دقت بالا متن را استخراج میکند و خطاهای تایپی کمتر میشود.
دیجیتالسازی بایگانیها
سازمانها میتوانند آرشیوهای کاغذی را به دادههای دیجیتال تبدیل کنند.

کاربردهای OCR در زندگی روزمره همه در جریان میباشد بدون اینکه متوجه آن باشیم .OCR فقط یک ابزار تئوری نیست و در بسیاری از صنایع استفاده میشود مانند:
بانکها برای پردازش چک و فرمها
فروشگاهها برای خواندن اطلاعات فاکتور
پلیس راهنمایی برای تشخیص پلاک خودرو
کتابخانهها برای دیجیتال کردن کتابها
اپلیکیشنهای ترجمه متن از روی تصویر
سیستمهای حسابداری برای استخراج اطلاعات رسید
وضعیت OCR در ایران
در سالهای اخیر OCR از یک فناوری تخصصی و محدود، به ابزاری کاربردی برای سازمانها، کسبوکارها و یا کاربران عادی تبدیل شده است. افزایش حجم اسناد کاغذی، توسعه خدمات دیجیتالی و نیاز به بایگانی هوشمند ، رشد اتوماسیون اداری باعث شده فناوری OCR بیش از گذشته مورد توجه قرار بگیرد. با این حال، OCR فارسی در ایران هنوز با چالشهایی مانند پیچیدگی خط فارسی، کیفیت پایین تری از اسناد اسکنشده و کمبود دادههای استاندارد روبهرو است.
اگرچه فناوری OCR در ایران رشد کرده، اما هنوز چند مانع مهم وجود دارد که کیفیت خروجی را تحت تأثیر قرار میدهد.
1. پیچیدگی زبان و خط فارسی
یکی از اصلیترین مشکلات، ماهیت خط فارسی است. در فارسی:
- حروف بههمچسبیده هستند
- شکل حروف بسته به موقعیت آنها تغییر میکند
- نقطهها و نشانهها بسیار مهماند
- تشخیص فاصله و نیمفاصله دشوار است
همین ویژگیها باعث میشوند OCR فارسی نسبت به زبانهایی مثل انگلیسی پیچیدهتر باشد.
2. کیفیت پایین اسناد
بخش زیادی از اسناد موجود در ایران:
- قدیمیاند
- کج اسکن شدهاند
- نور نامناسب دارند
- رزولوشن پایینی دارند
- دارای مهر، دستخط یا لکه هستند
این موارد دقت OCR را کاهش میدهند.
3. تنوع فونت و قالب
فونتهای مختلف فارسی، تایپ غیراستاندارد، فرمتهای قدیمی و طراحیهای نامنظم باعث میشوند استخراج متن با خطا همراه شود.
4. ضعف در دادههای آموزشی
برای توسعه OCR قدرتمند، نیاز به دادههای آموزشی استاندارد و گسترده وجود دارد. یکی از محدودیتهای بازار ایران، کمبود دیتاستهای باکیفیت برای متون فارسی، فرمها و اسناد واقعی است.
5. دستنوشته فارسی
تشخیص متن چاپی یک موضوع است و تشخیص دستخط فارسی موضوعی بسیار دشوارتر. در ایران، OCR برای متون دستنویس هنوز در بسیاری از سناریوها دقت کافی ندارد، مگر در شرایط کنترلشده.
وضعیت OCR در ایران نشان میدهد این فناوری از مرحله آشنایی اولیه عبور کرده و وارد فاز کاربردی شده است. با وجود چالشهایی مثل پیچیدگی خط فارسی، کیفیت پایین برخی اسناد و محدودیت دادههای آموزشی، بازار OCR فارسی در ایران در حال رشد است و در حوزههایی مانند بانکداری، بیمه، آموزش، اتوماسیون اداری و آرشیو دیجیتال کاربرد واقعی دارد.
اگر روند دیجیتالسازی در ایران ادامه پیدا کند، OCR به یکی از اجزای مهم زیرساخت پردازش اسناد تبدیل خواهد شد. در نتیجه، هم سازمانها و هم ارائهدهندگان فناوری فرصت زیادی برای توسعه این حوزه دارند.